

了解 xAI 的最新 AI 模型 Grok 3,并比较它与 OpenAI 的 o1 和 DeepSeek 的 R1 相比如何。
在上周发起收购 OpenAI 的竞标后,埃隆·马斯克通过他的公司 xAI 发布了Grok 3 ,称其为“目前世界上最强大的人工智能”。如果现场演示的基准测试结果成立,那么他可能是对的。
Grok 3 进入了不断发展的推理模型领域,与OpenAI 的 o1和DeepSeek 的 R1展开竞争。与 ChatGPT 等直接生成答案的通用模型不同,推理模型展示了其思维过程,在得出结论之前逐步分解问题。
然而,xAI 似乎将 Grok 3 定位为推理模型和通用 AI。关闭思考模式(稍后会详细介绍)时,它的功能类似于 GPT-4o 或 Claude 3.5 Sonnet——速度快、对话性强,专为一般任务而构建。但激活思考模式会将其转变为推理模型。
如果您没有时间听完 Grok 3 的一小时现场演示,请不要担心 – 我会消除干扰并为您分解要点。
并且,在学习了基础知识之后,您还需要观看我们关于 Grok 3 的视频,以了解它在推理、深度搜索功能和编码辅助方面与其他顶级 AI 模型进行测试时的表现如何:
什么是 Grok 3?
Grok 3 是 xAI 的最新 AI 模型,定位为 OpenAI 的 o1 和 DeepSeek 的 R1 的直接竞争对手。xAI 团队声称它比 Grok 2 强大 10 到 15 倍,并且根据演示中提供的基准,它实际上可能与市场上最好的模型相媲美。
推理模型有何不同?
如果您使用过 ChatGPT、Claude 或 Gemini,那么您就会熟悉大多数 AI 模型的工作方式:您提出一个问题,它们会生成一个答案,就这样。
Grok 3 等推理模型采用了不同的方法。它们不会立即给出答案,而是逐步分解问题,展示中间思路,甚至在给出最终答案之前完善输出。这使得它们在数学、编码和现实世界问题解决等任务中特别有用。
Grok 3 迷你
并非每个任务都需要 Grok 3 的全面推理。Grok 3 mini 针对速度和更低的计算使用率进行了优化,同时仍保留了 Grok 3 的推理能力。
对于想要在使用 API 时优化代币使用支出的开发人员来说,Grok 3 mini 特别有用。
我们还可以切换到 Grok 3 Mini,以便在聊天界面获得更快的响应。根据基准测试,它不会处理太多问题。
Grok 3 思考模式
思考模式是一种可选设置,可激活 Grok 3 的多步骤推理过程。它不会直接跳到答案,而是将问题分解为更小的步骤,评估不同的解决方案,并在输出最终结果之前完善其响应。

此模式对于解决复杂问题、数学证明、编码挑战和基于逻辑的任务特别有用。它模仿人类的结构化思维,非常适合推理质量比速度更重要的情况。
据我所知,xAI 将 Grok 3 定位为推理模型和通用模型。当关闭思考模式时,它的行为更像 GPT-4o 或Claude 3.5 Sonnet — 快速、对话性强且针对一般用途进行了优化。但当激活思考模式时,它会切换到推理模式,逐步分解复杂问题。
从基准测试来看,这种混合方法变得更加清晰。xAI 不仅将 Grok 3 与 OpenAI 的 O1 或 DeepSeek R1 等推理模型进行了比较,还将其与 GPT-4o、DeepSeek-V3 和 Claude 3.5 Sonnet 等通用模型进行了测试。这表明他们希望它在两个类别中都具有竞争力,而不是仅限于一个类别。
Grok 3 大脑模式
大脑模式是 Grok 3 的高性能设置,可分配额外的计算资源来处理艰巨的任务。
启用后,Grok 3 处理查询所需的时间更长,但可提供更高的准确性、更深入的洞察和更详细的响应。此模式特别适用于科学研究、多层 AI 任务和高度复杂的问题解决场景,在这些场景中,标准推理可能不够用。

Grok 3 深度搜索
DeepSearch 是 xAI 的内置研究工具,允许 Grok 3 在生成答案之前浏览网页、验证来源并综合实时信息。
与依赖预训练数据的标准 AI 模型不同,DeepSearch 会收集新鲜信息,因此非常适合新闻、市场趋势、技术研究和事实核查。此模式将 Grok 3 定位为 Gemini 的 Deep Research 和OpenAI 的 Deep Research的竞争对手。

Grok 3 是如何开发的?
Grok 3 建立在重大基础设施升级、新训练技术和大规模计算能力提升的基础上。与在相对有限的硬件上进行训练的前辈不同,xAI 现在已经构建了世界上最大的 AI 训练集群之一来支持 Grok 3 的开发。

Colossus:xAI 的定制超级计算机
训练大规模 AI 模型的最大挑战之一是计算可用性。为了解决这个问题,xAI 构建了自己的超级计算机集群 Colossus(您可以在上图中看到仓库)。
一期仅用122天就建成,部署了10万块H100 GPU,成为全球最大的AI训练集群之一。
在第二阶段,xAI 又在 92 天内将计算能力翻了一番。该基础设施允许持续训练,这意味着随着越来越多的用户与其互动,Grok 3 仍在实时改进。
从 Grok 0 到 Grok 3
Grok 1 于 2023 年 11 月发布,虽然它很有个性,但远不及 GPT-4o 或 Claude 3.5 Sonnet 的水平。几个月后,Grok 2 也发布了,虽然有了很大的改进,但仍然落后于顶级模型。
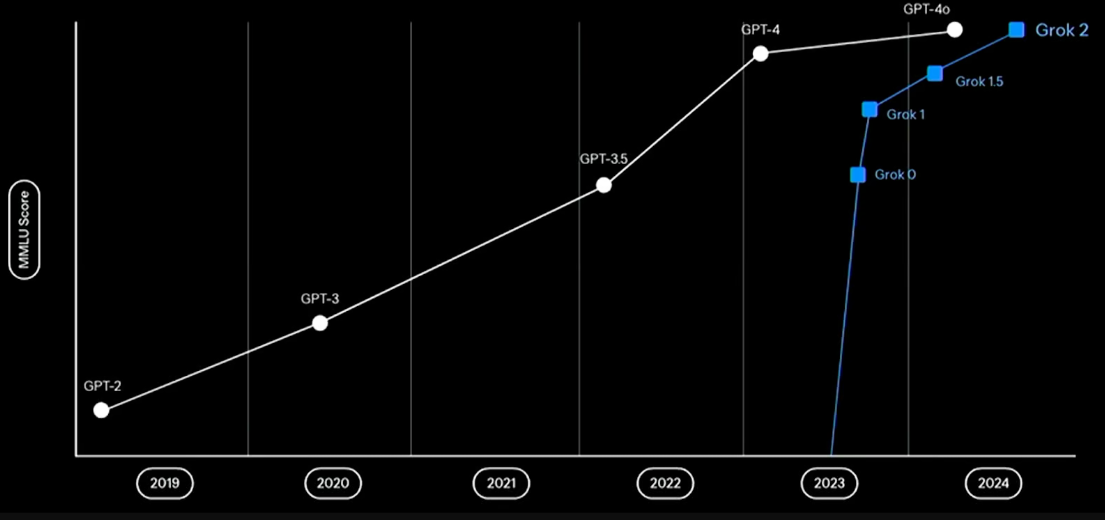
然而,Grok 3 标志着一次更大的飞跃。该团队声称,Grok 3 比 Grok 2 强大 10-15 倍,这要归功于模型改进和训练计算的大幅增加。
Grok 3 基准
xAI 声称 Grok 3 是迄今为止最强大的 AI 模型之一,其现场演示的基准测试表明它实际上可能与最好的模型相媲美。让我们将结果细分为数学、科学和编码,看看它与 GPT-4o、Claude 3.5 Sonnet、Gemini-2 Pro 和 DeepSeek-V3 以及其他推理模型(如 O1 和 DeepSeek-R1)相比如何。
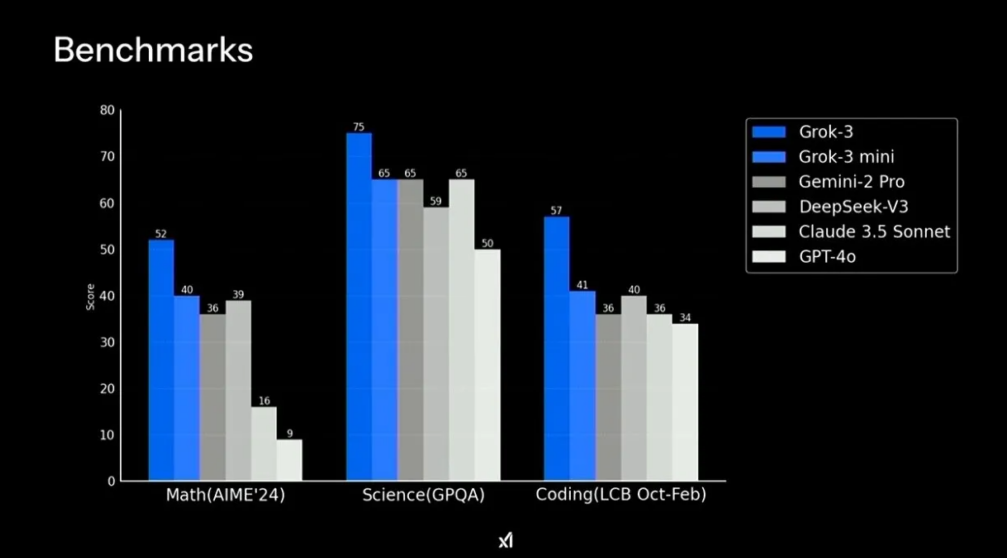
与通用模型相比的表现
第一组基准测试将 Grok 3 和 Grok 3 Mini 与其他通用模型进行了比较。
Grok 3 在所有类别中都遥遥领先,但数学、科学和编码仅代表通用模型用例的一小部分——人们还依靠它来编写、分析报告、提供客户支持等。
看看 Grok 3 在 MMLU(涵盖 57 个学科的广泛知识)、BBH(复杂推理和抽象问题解决)或 TruthfulQA(回答模糊或有争议问题的准确性)等基准测试中的表现会很有趣,以更全面地了解其实际能力。
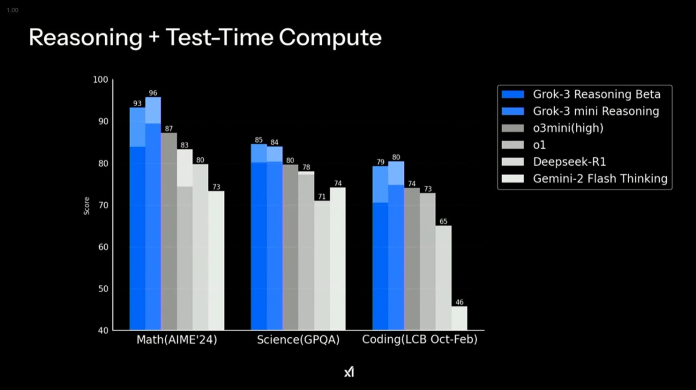
针对推理模型的表现
当 Grok 3 的推理能力得到充分利用时(即开启思考模式和大脑模式),模型的性能会显著提升。第二组基准测试将 Grok 3 Reasoning Beta 和 Grok 3 mini Reasoning 与其他高级推理模型(包括 O1、DeepSeek-R1 和Gemini-2 Flash Thinking)进行了比较。
Grok 3 的推理能力将其数学成绩提升至 93-96,比其通才模式 (52) 有了巨大的飞跃。
科学和编码分数也显著提高,超越了o1、DeepSeek-R1和Gemini-2 Flash Thinking。
Grok 3 mini Reasoning 在推理任务中的表现与完整版 Grok 3 相当(甚至更好——我不得不承认,那些颜色层的图表有点令人困惑),这意味着即使是较小的变体在复杂问题解决中仍然具有竞争力。
如何访问 Grok 3?
xAI 正在逐步推出 Grok 3,预计未来几个月内将有更广泛的可用性。我们将能够在基于聊天的界面和通过 API 使用 Grok 3。
基于聊天的界面
该模型目前已集成到 X(以前称为 Twitter)中,可供 Premium+ 订阅者使用。用户可以直接在平台内与其聊天,就像以前的 Grok 版本一样。您可以在左侧菜单中找到 Grok 按钮:

除了 X,xAI 还推出了grok.com,这是一个独立的网络界面,用户可以在社交媒体平台之外与模型进行交互。欧盟和英国目前还无法通过该网站访问 Grok。
还有专门的移动应用程序,但仅适用于 iOS。
Grok 3 API
截至本文发表时,Grok 3 尚未通过 API 发布,但可能很快就会推出。请关注模型页面以获取最新更新。
结论
Grok 3 无疑是 xAI 迄今为止最雄心勃勃的版本,但我还在等待看它在自己的演示基准之外的表现如何。目前,它看起来像一个可靠的推理模型,在多步骤问题解决方面可与 OpenAI 和 DeepSeek 相媲美。
这种混合方法(可以在快速对话式回复和思考模式的深度推理之间切换)在理论上是合理的。但我想看看它在数学、编码和科学之外的实际推广效果如何,特别是在写作、总结和现实世界研究等任务中。